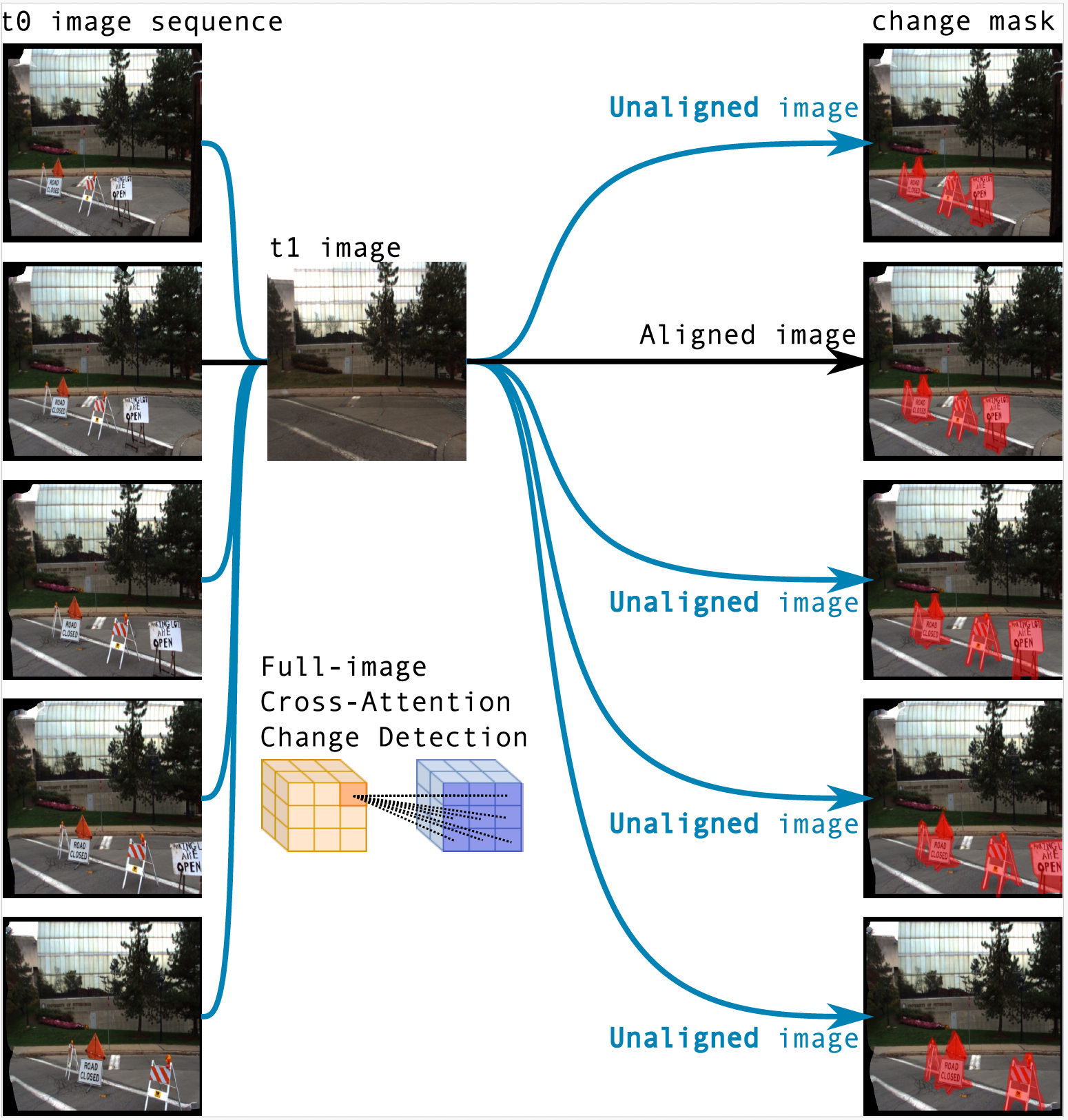
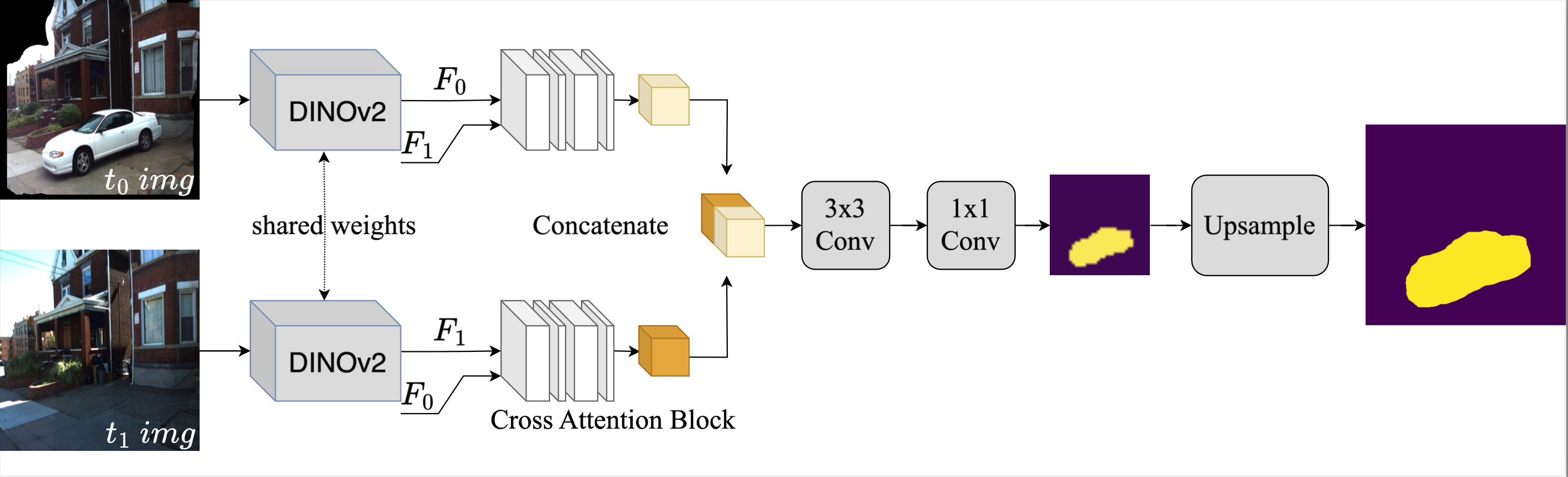
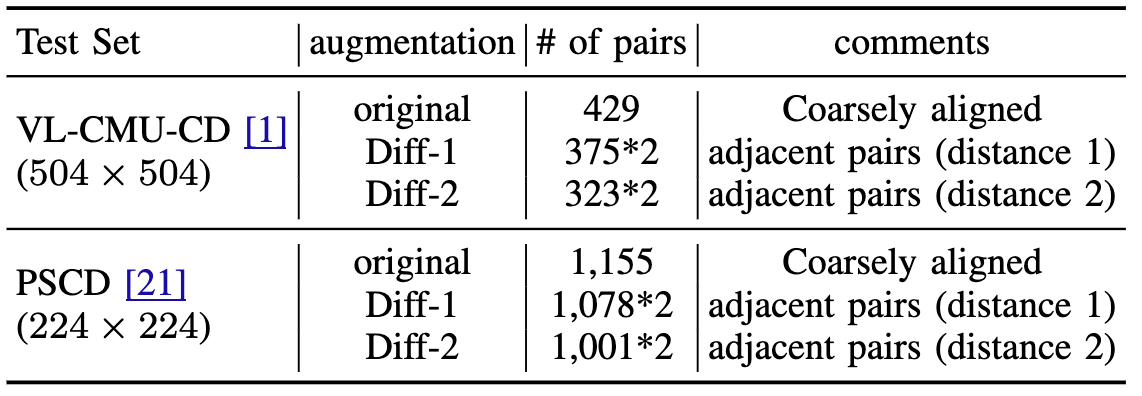
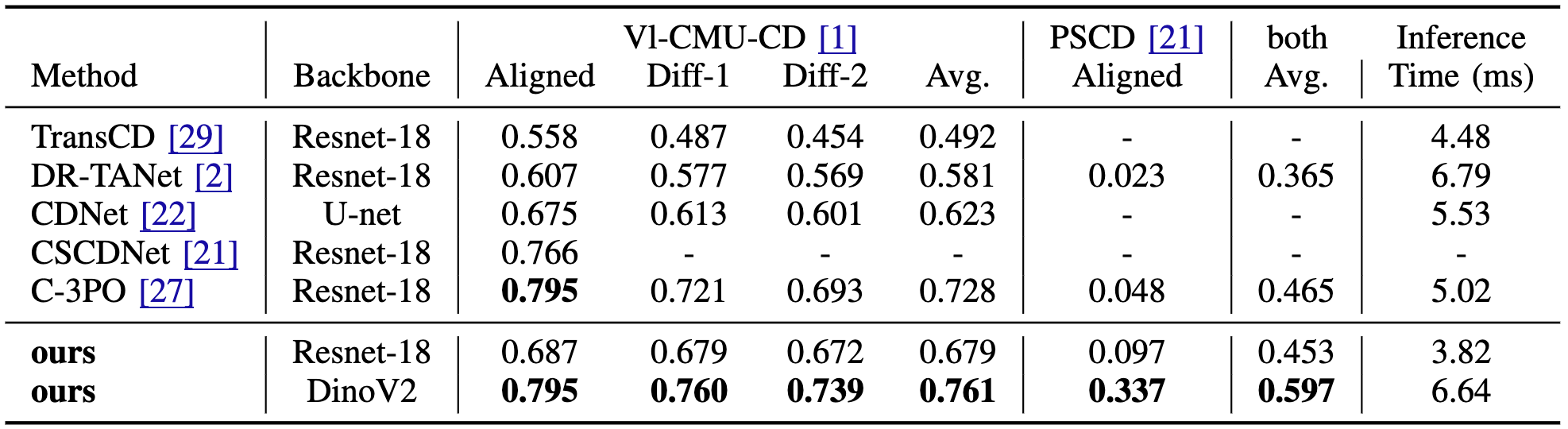
We present a novel method for scene change detection that leverages the robust feature extraction capabilities of a visual foundational model, DINOv2, and integrates fullimage cross-attention to address key challenges such as varying lighting, seasonal variations, and viewpoint differences. In order to effectively learn correspondences and mis-correspondences between an image pair for the change detection task, we propose to a) “freeze” the backbone in order to retain the generality of dense foundation features, and b) employ “fullimage” cross-attention to better tackle the viewpoint variations between the image pair. We evaluate our approach on two benchmark datasets, VL-CMU-CD and PSCD, along with their viewpoint-varied versions. Our experiments demonstrate significant improvements in F1-score, particularly in scenarios involving geometric changes between image pairs. The results indicate our method’s superior generalization capabilities over existing state-of-the-art approaches, showing robustness against photometric and geometric variations as well as better overall generalization when fine-tuned to adapt to new environments. Detailed ablation studies further validate the contributions of each component in our architecture. Our source code is available at: https://github.com/ChadLin9596/Robust-SceneChange-Detection.






@misc{lin2024robustscenechangedetection,
title={Robust Scene Change Detection Using Visual Foundation Models and Cross-Attention Mechanisms},
author={Chun-Jung Lin and Sourav Garg and Tat-Jun Chin and Feras Dayoub},
year={2024},
eprint={2409.16850},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2409.16850},
}